

适用硬件: Orange Pi AIpro (20T) 核心芯片: 华为昇腾 Ascend 310B 目标: 从零开始烧写系统,配置环境,并跑通 NPU 推理。
第一步:系统烧写与基础配置
注意:昇腾 NPU 对内核版本要求极高,严禁随意升级 Linux 内核或使用非官方镜像,否则 NPU 驱动会直接失效。
1.1 准备工作
-
TF 卡: 建议 32GB 以上(推荐 SanDisk Class 10 高速卡)。
-
读卡器: USB 3.0 读卡器。
-
镜像: Orange Pi 官方 Ubuntu 镜像 (推荐 Desktop 版本,方便调试)。
-
烧写工具: BalenaEtcher。
1.2 镜像烧写
-
解压下载的
.img.xz或.img镜像文件。 -
打开 BalenaEtcher,选择镜像文件,选择 TF 卡,点击 Flash。
-
烧写完成后,将卡插入开发板,连接电源(Type-C PD 65W)和 HDMI 显示
1.3 首次启动与登录
-
默认用户/密码:
HwHiAiUser/Mind@123 -
Root 用户/密码:
root/Mind@123 -
网络连接: 插入网线或点击桌面右上角连接 Wi-Fi,连接网络之后可以提供ssh远程连接或者安装vnc之后实现远程桌面,可不用显示屏了。
第二步:安装 CANN 开发套件与算子包 (核心)
这是最关键的一步。NPU 要工作,必须安装 Toolkit (开发工具集) 和 Kernels (算子二进制包)。 注意:官方镜像通常预置了基础驱动,但如果你需要升级或重新配置,请按以下步骤操作。
2.1. 下载软件包
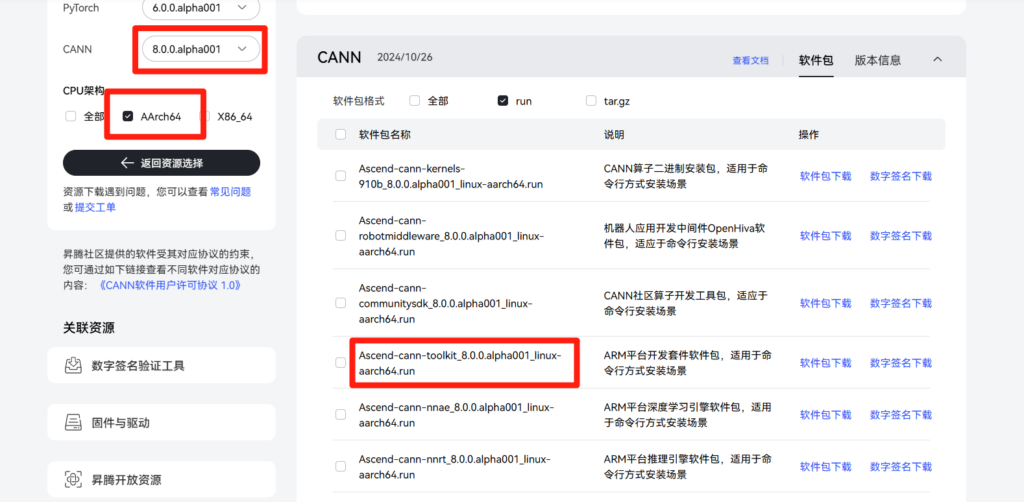
前往昇腾开发资源下载中心,下载适配 AArch64 (ARM64) 架构的 run 包:

-
Toolkit:
Ascend-cann-toolkit_8.0.0.alpha001_linux-aarch64.run(版本号可能不同,以实际为准)
-
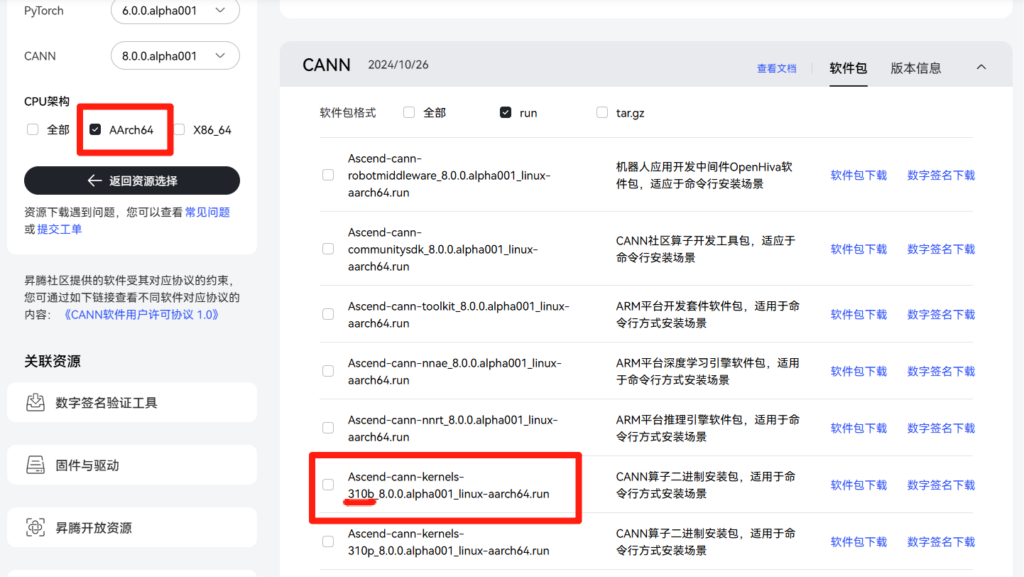
Kernels:
Ascend-cann-kernels-310b_8.0.0.alpha001_linux-aarch64.run(310B 专用算子包,加速编译)
2.2. 安装 Toolkit (开发套件)
在终端中进入下载目录,执行安装:
# 1. 赋予执行权限
chmod +x Ascend-cann-toolkit_8.0.0.alpha001_linux-aarch64.run# 2. 校验软件包
./Ascend-cann-toolkit_8.0.0.alpha001_linux-aarch64.run –check# 3. 安装软件包
./Ascend-cann-toolkit_8.0.0.alpha001_linux-aarch64.run –install
-
成功标志:终端显示
Ascend-cann-toolkit_8.0.0.alpha001_linux-aarch64.run install success。 - 这里check和install前面是两个小横线,不知为何发布出去就变了。
2.3. 安装 Kernels (算子包)
这一步是为了让 NPU 在运行推理时,直接调用预编译好的二进制算子,避免现场编译(解决“慢”和“卡”的问题)。
# 1. 赋予执行权限
chmod +x Ascend-cann-kernels-310b_8.0.0.alpha001_linux-aarch64.run# 2. 校验软件包
./Ascend-cann-kernels-310b_8.0.0.alpha001_linux-aarch64.run –check# 3. 安装软件包
./Ascend-cann-kernels-310b_8.0.0.alpha001_linux-aarch64.run –install
-
成功标志:终端显示
Ascend-cann-kernels-310b_8.0.0.alpha001_linux-aarch64.run install sucess。 - 这里check和install前面是两个小横线,不知为何发布出去就变了。
2.4. 配置环境变量 (必做!)
安装完后,必须告诉系统 NPU 库在哪里。
# 环境变量固化到
~/.bashrc中
echo “source /usr/local/Ascend/ascend-toolkit/set_env.sh” >> ~/.bashrc
echo “export TASK_QUEUE_ENABLE=0” >> ~/.bashrc
echo “export ACL_PRECISION_MODE=allow_fp32_to_fp16” >> ~/.bashrc# 使其生效
source ~/.bashrc
2.5. 验证安装
输入以下命令,确认 NPU 驱动和软件栈正常:
npu-smi info
看到 Health: OK 或 Alarm,且能看到 Chip ID 为 310B1,说明地基打好。

第三步:搭建 Python 与 Conda 环境
为了不把系统自带的 Python 搞乱,我们使用 Conda 来管理环境。
3.1. 安装 Miniforge (ARM64版 Conda)
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-aarch64.sh
bash Miniforge3-Linux-aarch64.sh# 安装完后重启终端或刷新环境变量
source ~/.bashrc
3.2. 创建专用虚拟环境
# 创建一个名为 npu_env 的环境,使用 Python 3.9 (兼容性最佳)
conda create -n npu_env python=3.9 -y# 激活环境
conda activate npu_env
第四步:安装 PyTorch 与 NPU 插件
昇腾 NPU 需要专用的 torch_npu 插件才能工作。
4.1. 安装依赖
pip install numpy==1.26.4 scipy psutil cloudpickle ml-dtypes tornado pyyaml attrs decorator sympy requests
4.2. 安装 PyTorch 和 Torch-NPU
此处选择CANN 8.0.0, torch 2.1.0, python 3.9
注意版本对应! (例如 Torch 2.1.0 必须配 Torch-NPU 2.1.0)。
-
方式一:下载 whl 包本地安装 (推荐)
# 安装torch 2.1.0(CPU版本) pip3 install torch==2.1.0 -f https://download.pytorch.org/whl/torch_stable.html
# 安装torch_npu
# 下载插件包
wget https://gitee.com/ascend/pytorch/releases/download/v6.0.0-pytorch2.1.0/torch_npu-2.1.0.post10-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl# 安装命令
pip3 install torch_npu-2.1.0.post10-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
-
方式二:在线安装
# 使用华为云镜像(官方源,通常最稳定)
pip install torch-npu==2.1.0.post6 -i https://repo.huaweicloud.com/repository/pytorch-proxy/simple/# 使用阿里云镜像
pip install torch-npu==2.1.0.post6 -i https://mirrors.aliyun.com/pypi/simple/
4.3. 简单验证
安装完成后,直接在终端执行以下命令,验证 NPU 是否被 PyTorch 成功接管:
python -c “import torch; import torch_npu; print(f’NPU状态: {torch.npu.is_available()}, 设备型号: {torch.npu.get_device_name(0)}’)”
预期输出:NPU状态: True, 设备型号: Ascend310B1 
第五步:运行 NPU 最小工作示例(矩阵运算)
环境搭好了,我们写一个脚本来验证 NPU 是否真的在进行矩阵计算,并与CPU运算结果进行对比。
5.1.创建测试脚本
新建文件 test_npu.py,写入以下代码:
import torch
import torch_npu
import time
# 定义矩阵大小
N = 2048
LOOP_TIMES = 10
print(f"=== 开始性能对比测试 (矩阵大小: {N}x{N}) ===")
# 1. CPU 测试部分
print("\n[1/2] 正在进行 CPU 测试...")
device_cpu = torch.device("cpu")
#生成数据
a_cpu = torch.randn(N, N, device=device_cpu)
b_cpu = torch.randn(N, N, device=device_cpu)
# CPU 预热 (Warm-up)
c_cpu = torch.matmul(a_cpu, b_cpu)
cpu_times = []
for i in range(1, LOOP_TIMES + 1):
t_start = time.time()
# 计算
c_cpu = torch.matmul(a_cpu, b_cpu)
t_end = time.time()
cost = t_end - t_start
cpu_times.append(cost)
print(f" CPU 第 {i} 次耗时: {cost:.6f} 秒")
avg_cpu_time = sum(cpu_times) / len(cpu_times)
print(f" >>> CPU 平均耗时: {avg_cpu_time:.6f} 秒")
# 2. NPU 测试部分
print("\n[2/2] 正在进行 NPU 测试...")
device_npu = torch.device("npu:0")
# 生成数据 (直接在NPU上生成,或者从CPU搬运)
# 为了纯粹测试计算能力,我们先将数据搬运好,不把搬运时间算在计算耗时里
a_npu = a_cpu.to(device_npu)
b_npu = b_cpu.to(device_npu)
# NPU 预热 (Warm-up) - 这一点对 NPU/GPU 非常重要
c_npu = torch.matmul(a_npu, b_npu)
torch.npu.synchronize() # 确保预热完成
npu_times = []
for i in range(1, LOOP_TIMES + 1):
# NPU 是异步执行的,必须同步后开始计时
torch.npu.synchronize()
t_start = time.time()
# 计算
c_npu = torch.matmul(a_npu, b_npu)
# 再次同步,确保计算真正结束
torch.npu.synchronize()
t_end = time.time()
cost = t_end - t_start
npu_times.append(cost)
print(f" NPU 第 {i} 次耗时: {cost:.6f} 秒")
avg_npu_time = sum(npu_times) / len(npu_times)
print(f" >>> NPU 平均耗时: {avg_npu_time:.6f} 秒")
# 3. 结果汇总
print("\n" + "=" * 40)
print("测试结果汇总:")
print(f"矩阵规模: {N} x {N}")
print(f"CPU 平均耗时: {avg_cpu_time:.6f} s")
print(f"NPU 平均耗时: {avg_npu_time:.6f} s")
if avg_npu_time > 0:
speedup = avg_cpu_time / avg_npu_time
print(f"NPU 相比 CPU 加速比: {speedup:.2f} 倍")
else:
print("NPU 耗时过短,无法计算准确加速比")
print("=" * 40)5.2. 运行脚本
在运行脚本之前,必须确保 CANN 环境变量 已加载,且 Conda 虚拟环境 已激活。
请严格按照以下顺序执行命令:
# 1. 加载 CANN 系统变量 (确保 NPU 驱动被识别) source ~/.bashrc# 2. 激活 Python 虚拟环境 (确保能找到 torch_npu 库) conda activate npu_env# 3. 运行脚本 python test_npu.py
为什么要这么做?
-
source ~/.bashrc: 你的.bashrc里记录了昇腾 Toolkit 的路径(如LD_LIBRARY_PATH)。如果不运行这一步,Python 找不到 NPU 的底层驱动文件(.so库)。 -
conda activate npu_env: 你的 PyTorch 和 torch_npu 是装在这个虚拟环境里的。如果不激活,系统默认使用基础 Python,它是没有 NPU 插件的。
5.3. 运行结果
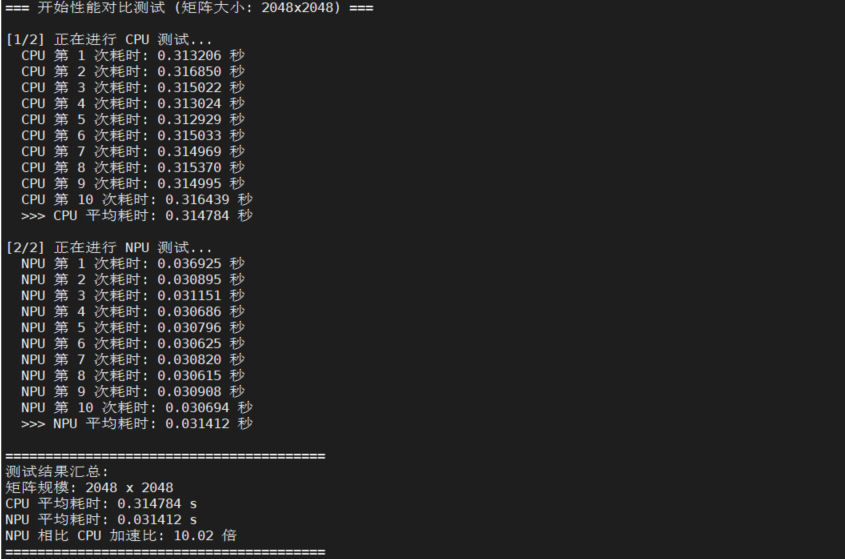
- CPU 跑分(基准线):
- 耗时稳定在 0.31 秒 左右。
- 这是通用 CPU 处理 2048×2048 矩阵乘法的正常物理极限,代表了“未加速”的状态。
- NPU 跑分(加速后):
- 耗时稳定在 0.03 秒 左右。
- 关键点:NPU 的耗时仅为 CPU 的 1/10。这种数量级的差异(10倍或更高)是软件优化无法做到的,只能是硬件加速的结果。
这里NPU的远行时间会很长,主要是因为:
- 首次运行 NPU 需要“预热”,包括算子编译,内存分配和Stream的建立。
- 数据搬运耗时。
- 任务量太小,NPU 适合干重活(如深度学习模型),不适合干琐碎的小活。
结论:只要看到 NPU 平均耗时 远低于 CPU 平均耗时(并在结尾看到 加速比 > 1,例如你的 10.02 倍),即证明 Ascend 310B NPU 已经成功被唤醒并完美接管了计算任务!
没有回复内容