

📝 前言与场景
在昇腾边缘计算板(如基于 Ascend 310B4 的开发板)上部署 AI 应用时,常规做法是使用 aclmdlLoadFromFile 接口从文件读取模型。这种做法不仅会带来文件系统的 I/O 延迟,且在拷贝部署时经常因为漏掉几十兆的 .om 模型文件而导致程序崩溃。
为了实现真正的“单文件绿色版”极速部署,本文分享一个进阶方案:利用 xxd 工具将 OM 模型转换为 C 语言数组硬编码到内存中。
为了彻底避免大家在网页上复制 C++ 和 CMake 代码时,因为不可见的隐藏字符导致编译报错,本文所有代码均使用 Shell 脚本一键生成。你只需要复制并在终端执行即可!
🛠️ 第一阶段:模型“锻造”为头文件 (xxd 魔法)
假设我们已经得到了转换好的模型 yolo26s-pose_aipp.om。
打开 WSL 终端,进入模型所在目录,执行以下指令将二进制模型转为十六进制的 .cpp 源码:
# 1. 确保 xxd 已安装 (Ubuntu 默认自带)
# 2. 将 om 文件转换为十六进制数组,直接生成源文件 (避免 include 导致编译爆内存)
xxd -i yolo26s-pose_aipp.om > /mnt/d/work/Ascend/yolo26_deploy/src/model_data.cpp⚠️ 关键提醒: xxd 会将文件名中的 - 和 . 替换为下划线 _。所以变量名会变成 yolo26s_pose_aipp_om 和 yolo26s_pose_aipp_om_len。
⚙️ 第二阶段:一键生成 C++ 核心代码与 CMake 配置
为防止网页复制带来格式错误,请直接在存放 model_data.cpp 的同级目录下,复制并运行以下完整的 Shell 块。
这段脚本会自动为你创建 src 目录,并将进阶版的 main.cpp(包含输入输出显存申请、实际推理执行和结果打印)以及配套的 CMakeLists.txt 安全地写入文件中:
# 进入相关目录
cd /mnt/d/work/Ascend/yolo26_deploy
# ==========================================
# 1. 一键生成 main.cpp
# ==========================================
cat << 'EOF' > src/main.cpp
#include <iostream>
#include <vector>
#include <cstdint>
#include <cstring>
#include "acl/acl.h"
// 外部链接 xxd 生成的模型数组
extern unsigned char yolo26s_pose_aipp_om[];
extern unsigned int yolo26s_pose_aipp_om_len;
int main() {
std::cout << "[INFO] ========== Ascend 310B4 Inference Start ==========" << std::endl;
// 1. 初始化与设备挂载
aclInit(nullptr);
aclrtSetDevice(0);
// 2. 从内存直接加载模型
uint32_t modelId = 0;
std::cout << "[INFO] Loading model from memory, size: " << yolo26s_pose_aipp_om_len << " bytes..." << std::endl;
aclError ret = aclmdlLoadFromMem(yolo26s_pose_aipp_om, yolo26s_pose_aipp_om_len, &modelId);
if (ret != ACL_SUCCESS) {
std::cerr << "[ERROR] Model load failed! Code: " << ret << std::endl;
if (ret == 500002) {
std::cerr << "[DIAGNOSIS] 500002: Version mismatch between ATC and Device Driver." << std::endl;
}
aclrtResetDevice(0);
aclFinalize();
return -1;
}
std::cout << "[SUCCESS] Model loaded! ID: " << modelId << std::endl;
// 3. 获取模型描述
aclmdlDesc *modelDesc = aclmdlCreateDesc();
aclmdlGetDesc(modelDesc, modelId);
std::cout << "[INFO] Creating buffers for inference..." << std::endl;
// 4. 构建输入数据 (申请 NPU 显存并喂入全 0 的黑图)
size_t inputSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
void *inputDeviceMem = nullptr;
aclrtMalloc(&inputDeviceMem, inputSize, ACL_MEM_MALLOC_HUGE_FIRST);
std::vector<uint8_t> dummyImage(inputSize, 0);
aclrtMemcpy(inputDeviceMem, inputSize, dummyImage.data(), inputSize, ACL_MEMCPY_HOST_TO_DEVICE);
aclDataBuffer *inputData = aclCreateDataBuffer(inputDeviceMem, inputSize);
aclmdlDataset *inputDataset = aclmdlCreateDataset();
aclmdlAddDatasetBuffer(inputDataset, inputData);
// 5. 构建输出数据 (申请 NPU 显存接结果)
size_t outputSize = aclmdlGetOutputSizeByIndex(modelDesc, 0);
void *outputDeviceMem = nullptr;
aclrtMalloc(&outputDeviceMem, outputSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclDataBuffer *outputData = aclCreateDataBuffer(outputDeviceMem, outputSize);
aclmdlDataset *outputDataset = aclmdlCreateDataset();
aclmdlAddDatasetBuffer(outputDataset, outputData);
// 6. 执行推理
std::cout << "[INFO] Executing Model on NPU..." << std::endl;
ret = aclmdlExecute(modelId, inputDataset, outputDataset);
if (ret == ACL_SUCCESS) {
std::cout << "[SUCCESS] Inference Finished Successfully!" << std::endl;
} else {
std::cerr << "[ERROR] Inference Failed! Code: " << ret << std::endl;
}
// 7. 取回结果并打印 (Device -> Host)
std::vector<float> hostOutputResult(outputSize / sizeof(float));
aclrtMemcpy(hostOutputResult.data(), outputSize, outputDeviceMem, outputSize, ACL_MEMCPY_DEVICE_TO_HOST);
std::cout << "\n================= INFERENCE RESULT =================" << std::endl;
std::cout << "Output Buffer Size: " << outputSize << " bytes." << std::endl;
std::cout << "Raw Output Values (first 10 floats):" << std::endl;
for (int i = 0; i < 10 && i < hostOutputResult.size(); ++i) {
std::cout << hostOutputResult[i] << " ";
}
std::cout << "\n==================================================\n" << std::endl;
// 8. 释放资源
aclDestroyDataBuffer(inputData);
aclDestroyDataBuffer(outputData);
aclmdlDestroyDataset(inputDataset);
aclmdlDestroyDataset(outputDataset);
aclrtFree(inputDeviceMem);
aclrtFree(outputDeviceMem);
aclmdlDestroyDesc(modelDesc);
aclmdlUnload(modelId);
aclrtResetDevice(0);
aclFinalize();
std::cout << "[INFO] Ascend 310B4 Inference Complete. Resources freed." << std::endl;
return 0;
}
EOF
# ==========================================
# 2. 一键生成 CMakeLists.txt
# ==========================================
cat << 'EOF' > CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(yolo26_pose_app)
# 设置 ARM64 交叉编译器
set(CMAKE_C_COMPILER aarch64-linux-gnu-gcc)
set(CMAKE_CXX_COMPILER aarch64-linux-gnu-g++)
# 指定你的 Ascend Toolkit 目录
set(ASCEND_PATH ${CMAKE_CURRENT_SOURCE_DIR}/aarch64-linux)
include_directories(
${ASCEND_PATH}/include
${PROJECT_SOURCE_DIR}/include
)
link_directories(
${ASCEND_PATH}/lib64
${ASCEND_PATH}/lib64/stub
)
# 编译 src 下所有的 cpp (包含庞大的 model_data.cpp)
file(GLOB_RECURSE SRC_FILES ${PROJECT_SOURCE_DIR}/src/*.cpp)
add_executable(yolo26_pose_app ${SRC_FILES})
# 链接 AscendCL 核心库
target_link_libraries(yolo26_pose_app
ascendcl
-Wl,--allow-shlib-undefined
pthread
dl
rt
)
target_compile_options(yolo26_pose_app PUBLIC -std=c++11 -Wall)
EOF🔨 第三阶段:编译
代码生成完毕后,只需要执行标准的 CMake 编译流程即可:
# 进入构建目录
cd build
# 执行编译 (注意你的环境中需要存在 aarch64-linux 这个目录存放 stub 库)
rm -rf *
cmake ..
make -j8
编译完成后,你会得到一个体积硕大(包含了整个 OM 模型)的可执行文件 yolo26_pose_app。
🔨 第四阶段:部署
你现在可以拷贝 yolo26_pose_app 这一可执行文件到开发板上。
比如这里放到了/root/userdata/yolo26_pose_app
在开发板终端执行:
# CANN环境加载
export ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/7.0.RC1/aarch64-linux
export PATH=$ASCEND_HOME/atc/bin:$ASCEND_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ASCEND_HOME/lib64:$ASCEND_HOME/atc/lib64:$LD_LIBRARY_PATH
# 昇腾环境加载
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 查看当前环境
echo $ASCEND_HOME/
# 给可执行文件赋权限
chmod +R 777 yolo26_pose_app
# 运行
./yolo26_pose_app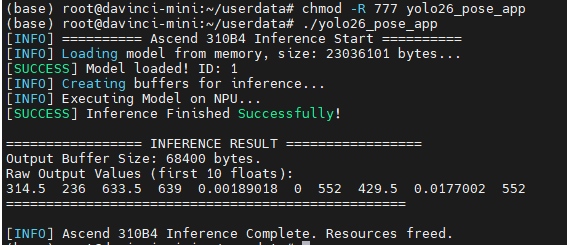
你将直接看到分配 NPU 显存、执行毫秒级硬件加速推理,并输出一串目标检测浮点张量结果的全过程!
🩸 第四阶段:实战避坑指南
-
❌ 坑点 1:编译报错
Killed(OOM 内存爆栈)-
根因: 模型文件太大,
model_data.cpp过长,执行make时 GCC 编译器耗尽了系统的可用内存。 -
方案: 这是为什么本文坚持不使用
#include直接包含模型数据,而是独立成model_data.cpp编译的原因。如果你的模型特别大依然报错,请尝试为 WSL 增加 Swap 虚拟内存,或考虑回归传统文件加载。
-
-
❌ 坑点 2:万恶的
500002 Version mismatch-
根因: 你在 PC 端用来做 ATC 模型转换的 CANN 版本,与开发板底层的
npu-smi驱动固件版本不一致。 -
方案: 永远确保转换环境和部署环境的底层驱动版本严格对齐!
-
没有回复内容